
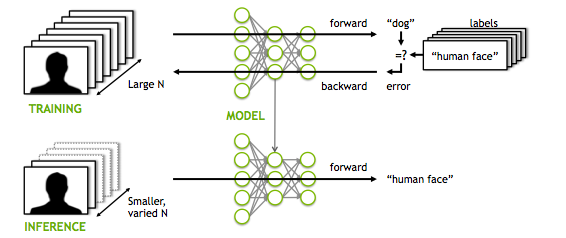
TENSOR FLOW
LOS TENSORES SON MATRICES, EN EL ESPACIO DIMENSIONAL R X R, DESARROLLADOS POR MINKOWSKY Y UTILIZADOS POR EINSTEIN PARA FORMULAR SU RELATIVIDAD ESPECIAL, PORQUE PUEDE MODELAR ESPACIOS CURVOS,
En matemáticas y en física, un tensor es cierta clase de entidad algebraica de varias componentes, que generaliza los conceptos de escalar, vector y matriz de una manera que sea independiente de cualquier sistema de coordenadas elegido. En adelante utilizaremos el convenio de sumación de Einstein.
Una vez elegida una base vectorial, las componentes de un tensor en una base vendrán dadas por una multimatriz. El orden de un tensor será el número de índices necesario para especificar sin ambigüedad una componente de un tensor: un escalar será considerado como un tensor de orden 0; un vector, un tensor de orden 1; y dada una base vectorial, los tensores de segundo orden pueden ser representados por una matriz.

TensorFlow™ is an open source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API. TensorFlow was originally developed by researchers and engineers working on the Google Brain Team within Google's Machine Intelligence research organization for the purposes of conducting machine learning and deep neural networks research, but the system is general enough to be applicable in a wide variety of other domains as well.

DESARROLLADO PRINCIPALMENTE EN PYTHON Y JAVA

TensorFlow es una biblioteca de código abierto para aprendizaje automático a través de un rango de tareas, y desarrollado por Google para satisfacer sus necesidades de sistemas capaces de construir y entrenar redes neuronales para detectar y decifrar patrones y correlaciones, análogos al aprendizaje y razonamiento usados por los humanos.1 Actualmente es utilizado tanto para la investigación como para la producción de productos de Google frecuentemente remplazando el rol de su predecesor de código cerrado, DistBelief. TensorFlow fue originalmente desarrolado por el equipo de Google Brain para uso interno en Google antes de ser publicado bajo la licencia de código abierto Apache 2.0 el 9 de noviembre 2015.
Instalacion en windows
https://www.tensorflow.org/install/install_windows
Deep learning
From Wikipedia, the free encyclopedia
For deep versus shallow learning in educational psychology, see Student approaches to learning.
| Machine learning and data mining |
|---|
 |
Deep learning (also known as deep structured learning, hierarchical learning or deep machine learning) is a class of machine learning algorithms that:[1](pp199–200)
- use a cascade of many layers of nonlinear processing units for feature extraction and transformation. Each successive layer uses the output from the previous layer as input. The algorithms may be supervised or unsupervised and applications include pattern analysis (unsupervised) and classification (supervised).
- are based on the (unsupervised) learning of multiple levels of features or representations of the data. Higher level features are derived from lower level features to form a hierarchical representation.
- are part of the broader machine learning field of learning representations of data.
- learn multiple levels of representations that correspond to different levels of abstraction; the levels form a hierarchy of concepts.
In a simple case, there might be two sets of neurons: one set that receives an input signal and one that sends an output signal. When the input layer receives an input it passes on a modified version of the input to the next layer. In a deep network, there are many layers between the input and the output (and the layers are not made of neurons but it can help to think of it that way), allowing the algorithm to use multiple processing layers, composed of multiple linear and non-linear transformations.[2][1][3][4][5][6][7][8][9]
Deep learning is part of a broader family of machine learning methods based on learning representations of data. An observation (e.g., an image) can be represented in many ways such as a vector of intensity values per pixel, or in a more abstract way as a set of edges, regions of particular shape, etc. Some representations are better than others at simplifying the learning task (e.g., face recognition or facial expression recognition[10]). One of the promises of deep learning is replacing handcrafted features with efficient algorithms for unsupervised or semi-supervised feature learning and hierarchical feature extraction.[11]
Research in this area attempts to make better representations and create models to learn these representations from large-scale unlabeled data. Some of the representations are inspired by advances in neuroscience and are loosely based on interpretation of information processing and communication patterns in a nervous system, such as neural coding which attempts to define a relationship between various stimuli and associated neuronal responses in the brain.[12]
Various deep learning architectures such as deep neural networks, convolutional deep neural networks, deep belief networks and recurrent neural networks have been applied to fields like computer vision, automatic speech recognition, natural language processing, audio recognition and bioinformatics where they have been shown to produce state-of-the-art results on various tasks.
NVIDIA GPUs - The Engine of Deep Learning
Traditional machine learning uses handwritten feature extraction and modality-specific machine learning algorithms to label images or recognize voices. However, this method has several drawbacks in both time-to-solution and accuracy.
Today’s advanced deep neural networks use algorithms, big data, and the computational power of the GPU to change this dynamic. Machines are now able to learn at a speed, accuracy, and scale that are driving true artificial intelligence and AI Computing
Deep learning is used in the research community and in industry to help solve many big data problems such as computer vision, speech recognition, and natural language processing. Practical examples include:
- Vehicle, pedestrian and landmark identification for driver assistance
- Image recognition
- Speech recognition and translation
- Natural language processing
- Life sciences

The NVIDIA Deep Learning SDK provides high-performance tools and libraries to power innovative GPU-accelerated machine learning applications in the cloud, data centers, workstations, and embedded platforms
NVIDIA TensorRT™ is a high performance neural network inference engine for production deployment of deep learning applications. TensorRT can be used to rapidly optimize, validate and deploy trained neural network for inference to hyperscale data centers, embedded, or automotive product platforms.
Developers can use TensorRT to deliver fast inference using INT8 or FP16 optimized precision that significantly reduces latency, as demanded by real-time services such as streaming video categorization on the cloud or object detection and segmentation on embedded and automotive platforms. With TensorRT developers can focus on developing novel AI-powered applications rather than performance tuning for inference deployment. TensorRT runtime ensures optimal inference performance that can meet the needs of even the most demanding throughput requirements.
TensorRT is available as a free download to the members of the NVIDIA Developer Program. If you are not already a member, clicking “Download” will ask you join the program.

(Click to Zoom)

(Click to Zoom)

(Click to Zoom)
My Top 9 Favorite Python Deep Learning Libraries
So you’re interested in deep learning and Convolutional Neural Networks. But where do you start? Which library do you use? There are just so many!
Inside this blog post, I detail 9 of my favorite Python deep learning libraries.
This list is by no means exhaustive, it’s simply a list of libraries that I’ve used in my computer vision career and found particular useful at one time or another.
Some of these libraries I use more than others — specifically, Keras, mxnet, and sklearn-theano.
Others, I use indirectly, such as Theano and TensorFlow (which libraries like Keras, deepy, and Blocks build upon).
And even others, I use only for very specific tasks (such as nolearn and their Deep Belief Network implementation).
The goal of this blog post is to introduce you to these libraries. I encourage you to read up on each them individually to determine which one will work best for you in your particular situation.
My Top 9 Favorite Python Deep Learning Libraries
Again, I want to reiterate that this list is by no means exhaustive. Furthermore, since I am a computer vision researcher and actively work in the field, many of these libraries have a strong focus on Convolutional Neural Networks (CNNs).
I’ve organized this list of deep learning libraries into three parts.
The first part details popular libraries that you may already be familiar with. For each of these libraries, I provide a very general, high-level overview. I then detail some of my likes and dislikes about each library, along with a few appropriate use cases.
The second part dives into my personal favorite deep learning libraries that I use heavily on a regular basis (HINT: Keras, mxnet, and sklearn-theano).
Finally, I provide a “bonus” section for libraries that I have (1) not used in a long time, but still think you may find useful or (2) libraries that I haven’t tried yet, but look interesting.
Let’s go ahead and dive in!
For starters:
1. Caffe
It’s pretty much impossible to mention “deep learning libraries” without bringing up Caffe. In fact, since you’re on this page right now reading up on deep learning libraries, I’m willing to bet that you’ve already heard of Caffe.
So, what is Caffe exactly?
Caffe is a deep learning framework developed by the Berkeley Vision and Learning Center (BVLC). It’s modular. Extremely fast. And it’s used by academics and industry in start-of-the-art applications.
In fact, if you were to go through the most recent deep learning publications (that also provide source code), you’ll more than likely find Caffe models on their associated GitHub repositories.
While Caffe itself isn’t a Python library, it does provide bindings into the Python programming language. We typically use these bindings when actually deploying our network in the wild.
The reason I’ve included Caffe in this list is because it’s used nearly everywhere. You define your model architecture and solver methods in a plaintext, JSON-like file called.prototxt configuration files. The Caffe binaries take these .prototxt files and train your network. After Caffe is done training, you can take your network and classify new images via Caffe binaries, or better yet, through the Python or MATLAB APIs.
While I love Caffe for its performance (it can process 60 million images per day on a K40 GPU), I don’t like it as much as Keras or mxnet.
The main reason is that constructing an architecture inside the .prototxt files can become quite tedious and tiresome. And more to the point, tuning hyperparameters with Caffe can not be (easily) done programmatically! Because of these two reasons, I tend to lean towards libraries that allow me to implement the end-to-end network (including cross-validation and hyperparameter tuning) in a Python-based API.
2. Theano
Let me start by saying that Theano is beautiful. Without Theano, we wouldn’t have anywhere near the amount of deep learning libraries (specifically in Python) that we do today. In the same way that without NumPy, we couldn’t have SciPy, scikit-learn, and scikit-image, the same can be said about Theano and higher-level abstractions of deep learning.
At the very core, Theano is a Python library used to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays. Theano accomplishes this via tight integration with NumPy and transparent use of the GPU.
While you can build deep learning networks in Theano, I tend to think of Theano as the building blocks for neural networks, in the same way that NumPy serves as the building blocks for scientific computing. In fact, most of the libraries I mention in this blog post wrap around Theano to make it more convenient and accessible.
Don’t get me wrong, I love Theano — I just don’t like writing code in Theano.
While not a perfect comparison, building a Convolutional Neural Network in Theano is like writing a custom Support Vector Machine (SVM) in native Python with only a sprinkle of NumPy.
Can you do it?
Sure, absolutely.
Is it worth your time and effort?
Eh, maybe. It depends on how low-level you want to go/your application requires.
Personally, I’d rather use a library like Keras that wraps Theano into a more user-friendly API, in the same way that scikit-learn makes it easier to work with machine learning algorithms.
3. TensorFlow
Similar to Theano, TensorFlow is an open source library for numerical computation using data flow graphs (which is all that a Neural Network really is). Originally developed by the researchers on the Google Brain Team within Google’s Machine Intelligence research organization, the library has since been open sourced and made available to the general public.
A primary benefit of TensorFlow (as compared to Theano) is distributed computing, particularly among multiple-GPUs (although this is something Theano is working on).
Other than swapping out the Keras backend to use TensorFlow (rather than Theano), I don’t have much experience with the TensorFlow library. Over the next few months, I expect this to change, however.
4. Lasagne
Lasagne is a lightweight library used to construct and train networks in Theano. The key term here is lightweight — it is not meant to be a heavy wrapper around Theano like Keras is. While this leads to your code being more verbose, it does free you from any restraints, while still giving you modular building blocks based on Theano.
Simply put: Lasagne functions as a happy medium between the low-level programming of Theano and the higher-level abstractions of Keras.
My Go-To’s:
5. Keras
If I had to pick a favorite deep learning Python library, it would be hard for me to pick between Keras and mxnet — but in the end, I think Keras might win out.
Really, I can’t say enough good things about Keras.
Keras is a minimalist, modular neural network library that can use either Theano or TensorFlow as a backend. The primary motivation behind Keras is that you should be able to experiment fast and go from idea to result as quickly as possible.
Architecting networks in Keras feels easy and natural. It includes some of the latest state-of-the-art algorithms for optimizers (Adam, RMSProp), normalization (BatchNorm), and activation layers (PReLU, ELU, LeakyReLU).
Keras also places a heavy focus on Convolutional Neural Networks, something very near to my heart. Whether this was done intentionally or unintentionally, I think this is extremely valuable from a computer vision perspective.
More to the point, you can easily construct both sequence-based networks (where the inputs flow linearly through the network) and graph-based networks (where inputs can “skip” certain layers, only to be concatenated later). This makes implementing more complex network architectures such as GoogLeNet and SqueezeNet much easier.
My only problem with Keras is that it does not support multi-GPU environments for training a network in parallel. This may or may not be a deal breaker for you.
If I want to train a network as fast as possible, then I’ll likely use mxnet. But if I’m tuning hyperparameters, I’m likely to setup four independent experiments with Keras (running on each of my Titan X GPUs) and evaluate the results.
6. mxnet
My second favorite deep learning Python library (again, with a focus on training image classification networks), would undoubtedly be mxnet. While it can take a bit more code to standup a network in mxnet, what it does give you is an incredible number of language bindings (C++, Python, R, JavaScript, etc.)
The mxnet library really shines for distributed computing, allowing you to train your network across multiple CPU/GPU machines, and even in AWS, Azure, and YARN clusters.
Again, it takes a little more code to get an experiment up and running in mxnet (as compared to Keras), but if you’re looking to distribute training across multiple GPUs or systems, I would use mxnet.
7. sklearn-theano
There are times where you don’t need to train a Convolutional Neural Network end-to-end. Instead, you need to treat the CNN as a feature extractor. This is especially useful in situations where you don’t have enough data to train a full CNN from scratch. Instead, just pass your input images through a popular pre-trained architecture such as OverFeat, AlexNet, VGGNet, or GoogLeNet, and extract features from the FC layers (or whichever layer you decide to use).
In short, this is exactly what sklearn-theano allows you to do. You can’t train a model from scratch with it — but it’s fantastic for treating networks as feature extractors. I tend to use this library as my first stop when evaluating whether a particular problem is suitable for deep learning or not.
8. nolearn
I’ve used nolearn a few times already on the PyImageSearch blog, mainly when performing some initial GPU experiments on my MacBook Pro and performing deep learning on an Amazon EC2 GPU instance.
While Keras wraps Theano and TensorFlow into a more user-friendly API, nolearn does the same — only for Lasagne. Furthermore, all code in nolearn is compatible with scikit-learn, a huge bonus in my book.
I personally don’t use nolearn for Convolutional Neural Networks (CNNs), although you certainly could (I prefer Keras and mxnet for CNNs) — I mainly use nolearn for its implementation of Deep Belief Networks (DBNs).
9. DIGITS
Alright, you got me.
DIGITS isn’t a true deep learning library (although it is written in Python). DIGITS (Deep Learning GPU Training System) is actually a web application used for training deep learning models in Caffe (although I suppose you could hack the source code to work with a backend other than Caffe, but that sounds like a nightmare).
If you’ve ever worked with Caffe before, then you know it can be quite tedious to define your .prototxt files, generate your image dataset, run your network, and babysit your network training all via your terminal. DIGITS aims to fix this by allowing you to do (most) of these tasks in your browser.
Furthermore, the user interface is excellent, providing you with valuable statistics and graphs as your model trains. I also like that you can easily visualize activation layers of the network for various inputs. Finally, if you have a specific image that you would like to test, you can either upload the image to your DIGITS server or enter the URL of the image and your Caffe model will automatically classify the image and display the result in your browser. Pretty neat!
BONUS:
10. Blocks
I’ll be honest, I’ve never used Blocks before, although I do want to give it a try (hence why I’m including it in this list). Like many of the other libraries in this list, Blocks builds on top of Theano, exposing a much more user friendly API.
11. deepy
If you were to guess which library deepy wraps around, what would your guess be?
That’s right, it’s Theano.
I remember using deepy awhile ago (during one if its first initial commits), but I haven’t touched it in a good 6-8 months. I plan on giving it another try in future blog posts.
12. pylearn2
I feel compelled to include pylearn2 in this list for historical reasons, even though I don’t actively use it anymore. Pylearn2 is more than a general machine learning library (similar to scikit-learn in that it respect), but also includes implementations of deep learning algorithms.
The biggest concern I have with pylearn2 is that (as of this writing), it does not have an active developer. Because of this, I’m hesitant to recommend pylearn2 over more maintained and active libraries such as Keras and mxnet.
13. Deeplearning4j
This is supposed to be a Python-based list, but I thought I would include Deeplearning4j in here, mainly out of the immense respect I have for what they are doing — building an open source, distributed deep learning library for the JVM.
If you work in enterprise, you likely have a basement full of servers you use for Hadoop and MapReduce. Maybe you’re still using these machines. Maybe you’re not.
But what if you could use these same machines to apply deep learning?
It turns out you can — you just need Deeplearning4j.
Take a deep dive into Deep Learning and Convolutional Neural Networks
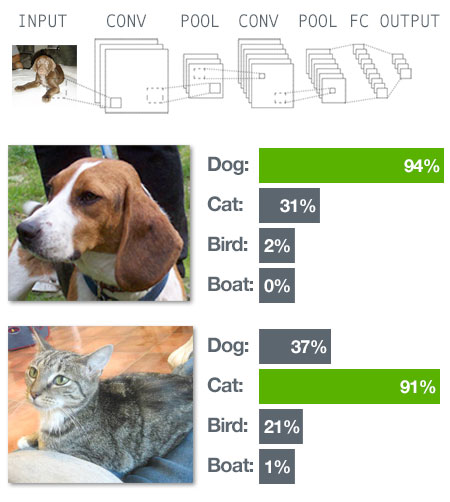
Figure 1: Learn how to utilize Deep Learning and Convolutional Neural Networks to classify the contents of images inside the PyImageSearch Gurus course.
Curious about deep learning?
I’m here to help.
Inside the PyImageSearch Gurus course, I’ve created 21 lessons covering 256 pages of tutorials on Neural Networks, Deep Belief networks, and Convolutional Neural Networks, allowing you to get up to speed qucikly and easily.
To learn more about the PyImageSearch Gurus course (and grab 10 FREE sample lessons), just click the button below:
Summary
In this blog post, I reviewed some of my favorite libraries for deep learning and Convolutional Neural Networks. This list was by no means exhaustive and was certainly biased towards deep learning libraries that focus on computer vision and Convolutional Neural Networks.
All that said, I do think this is a great list to utilize if you’re just getting started in the deep learning field and looking for a library to try out.
In my personal opinion, I find it hard to beat Keras and mxnet. The Keras library sits on top of computational powerhouses such as Theano and TensorFlow, allowing you to construct deep learning architectures in remarkably few lines of Python code.
And while it may take a bit more code to construct and train a network with mxnet, you gain the ability to distribute training across multiple GPUs easily and efficiently. If you’re in a multi-GPU system/environment and want to leverage this environment to its full capacity, then definitely give mxnet a try.
Before you go, be sure to sign up for the PyImageSearch Newsletter using the form below to be notified when new deep learning posts are published (there will be a lot of them in the coming months!)
http://deeplearning.net/tutorial/
Deep Learning Tutorials
Deep Learning is a new area of Machine Learning research, which has been introduced with the objective of moving Machine Learning closer to one of its original goals: Artificial Intelligence. See these course notes for a brief introduction to Machine Learning for AI and an introduction to Deep Learning algorithms.
Deep Learning is about learning multiple levels of representation and abstraction that help to make sense of data such as images, sound, and text. For more about deep learning algorithms, see for example:
- The monograph or review paper Learning Deep Architectures for AI (Foundations & Trends in Machine Learning, 2009).
- The ICML 2009 Workshop on Learning Feature Hierarchies webpage has a list of references.
- The LISA public wiki has a reading list and a bibliography.
- Geoff Hinton has readings from 2009’s NIPS tutorial.
The tutorials presented here will introduce you to some of the most important deep learning algorithms and will also show you how to run them using Theano. Theano is a python library that makes writing deep learning models easy, and gives the option of training them on a GPU.
The algorithm tutorials have some prerequisites. You should know some python, and be familiar with numpy. Since this tutorial is about using Theano, you should read over the Theano basic tutorial first. Once you’ve done that, read through our Getting Started chapter – it introduces the notation, and [downloadable] datasets used in the algorithm tutorials, and the way we do optimization by stochastic gradient descent.
The purely supervised learning algorithms are meant to be read in order:
- Logistic Regression - using Theano for something simple
- Multilayer perceptron - introduction to layers
- Deep Convolutional Network - a simplified version of LeNet5
The unsupervised and semi-supervised learning algorithms can be read in any order (the auto-encoders can be read independently of the RBM/DBN thread):
- Auto Encoders, Denoising Autoencoders - description of autoencoders
- Stacked Denoising Auto-Encoders - easy steps into unsupervised pre-training for deep nets
- Restricted Boltzmann Machines - single layer generative RBM model
- Deep Belief Networks - unsupervised generative pre-training of stacked RBMs followed by supervised fine-tuning
Building towards including the mcRBM model, we have a new tutorial on sampling from energy models:
- HMC Sampling - hybrid (aka Hamiltonian) Monte-Carlo sampling with scan()
- Building towards including the Contractive auto-encoders tutorial, we have the code for now:
- Contractive auto-encoders code - There is some basic doc in the code.
- Recurrent neural networks with word embeddings and context window:
- LSTM network for sentiment analysis:
- Energy-based recurrent neural network (RNN-RBM):
Note that the tutorials here are all compatible with Python 2 and 3, with the exception of Modeling and generating sequences of polyphonic music with the RNN-RBM which is only available for Python 2.
Very Brief Introduction to Machine Learning for AI
The topics summarized here are covered in these slides.
Intelligence
The notion of intelligence can be defined in many ways. Here we define it as the ability to take the right decisions, according to some criterion (e.g. survival and reproduction, for most animals). To take better decisions requires knowledge, in a form that is operational, i.e., can be used to interpret sensory data and use that information to take decisions.
Artificial Intelligence
Computers already possess some intelligence thanks to all the programs that humans have crafted and which allow them to “do things” that we consider useful (and that is basically what we mean for a computer to take the right decisions). But there are many tasks which animals and humans are able to do rather easily but remain out of reach of computers, at the beginning of the 21st century. Many of these tasks fall under the label of Artificial Intelligence, and include many perception and control tasks. Why is it that we have failed to write programs for these tasks? I believe that it is mostly because we do not know explicitly (formally) how to do these tasks, even though our brain (coupled with a body) can do them. Doing those tasks involve knowledge that is currently implicit, but we have information about those tasks through data and examples (e.g. observations of what a human would do given a particular request or input). How do we get machines to acquire that kind of intelligence? Using data and examples to build operational knowledge is what learning is about.
Machine Learning
Machine learning has a long history and numerous textbooks have been written that do a good job of covering its main principles. Among the recent ones I suggest:
- Chris Bishop, “Pattern Recognition and Machine Learning”, 2007
- Simon Haykin, “Neural Networks: a Comprehensive Foundation”, 2009 (3rd edition)
- Richard O. Duda, Peter E. Hart and David G. Stork, “Pattern Classification”, 2001 (2nd edition)
Here we focus on a few concepts that are most relevant to this course.
Formalization of Learning
First, let us formalize the most common mathematical framework for learning. We are given training examples
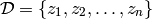
with the 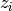 being examples sampled from an unknown process
being examples sampled from an unknown process 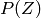 . We are also given a loss functional
. We are also given a loss functional 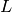 which takes as argument a decision function
which takes as argument a decision function 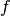 and an example
and an example  , and returns a real-valued scalar. We want to minimize the expected value of
, and returns a real-valued scalar. We want to minimize the expected value of 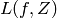 under the unknown generating process .
under the unknown generating process .
being examples sampled from an unknown process . We are also given a loss functional which takes as argument a decision function and an example , and returns a real-valued scalar. We want to minimize the expected value of under the unknown generating process .Supervised Learning
In supervised learning, each examples is an (input,target) pair: 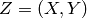 and takes an
and takes an 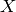 as argument. The most common examples are
as argument. The most common examples are
and takes an as argument. The most common examples are- regression:
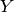 is a real-valued scalar or vector, the output of is in the same set of values as , and we often take as loss functional the squared error
is a real-valued scalar or vector, the output of is in the same set of values as , and we often take as loss functional the squared error
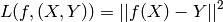
- classification: is a finite integer (e.g. a symbol) corresponding to a class index, and we often take as loss function the negative conditional log-likelihood, with the interpretation that
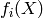 estimates
estimates 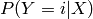 :
: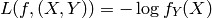 where we have the constraints
where we have the constraints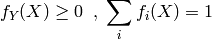
Unsupervised Learning
In unsupervised learning we are learning a function which helps to characterize the unknown distribution . Sometimes is directly an estimator of itself (this is called density estimation). In many other cases is an attempt to characterize where the density concentrates. Clustering algorithms divide up the input space in regions (often centered around a prototype example or centroid). Some clustering algorithms create a hard partition (e.g. the k-means algorithm) while others construct a soft partition (e.g. a Gaussian mixture model) which assign to each 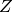 a probability of belonging to each cluster. Another kind of unsupervised learning algorithms are those that construct a new representation for . Many deep learning algorithms fall in this category, and so does Principal Components Analysis.
a probability of belonging to each cluster. Another kind of unsupervised learning algorithms are those that construct a new representation for . Many deep learning algorithms fall in this category, and so does Principal Components Analysis.
which helps to characterize the unknown distribution . Sometimes is directly an estimator of itself (this is called density estimation). In many other cases is an attempt to characterize where the density concentrates. Clustering algorithms divide up the input space in regions (often centered around a prototype example or centroid). Some clustering algorithms create a hard partition (e.g. the k-means algorithm) while others construct a soft partition (e.g. a Gaussian mixture model) which assign to each a probability of belonging to each cluster. Another kind of unsupervised learning algorithms are those that construct a new representation for . Many deep learning algorithms fall in this category, and so does Principal Components Analysis.Local Generalization
The vast majority of learning algorithms exploit a single principle for achieving generalization: local generalization. It assumes that if input example 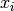 is close to input example
is close to input example 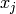 , then the corresponding outputs
, then the corresponding outputs 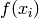 and
and 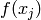 should also be close. This is basically the principle used to perform local interpolation. This principle is very powerful, but it has limitations: what if we have to extrapolate? or equivalently, what if the target unknown function has many more variations than the number of training examples? in that case there is no way that local generalization will work, because we need at least as many examples as there are ups and downs of the target function, in order to cover those variations and be able to generalize by this principle. This issue is deeply connected to the so-called curse of dimensionality for the following reason. When the input space is high-dimensional, it is easy for it to have a number of variations of interest that is exponential in the number of input dimensions. For example, imagine that we want to distinguish between 10 different values of each input variable (each element of the input vector), and that we care about about all the
should also be close. This is basically the principle used to perform local interpolation. This principle is very powerful, but it has limitations: what if we have to extrapolate? or equivalently, what if the target unknown function has many more variations than the number of training examples? in that case there is no way that local generalization will work, because we need at least as many examples as there are ups and downs of the target function, in order to cover those variations and be able to generalize by this principle. This issue is deeply connected to the so-called curse of dimensionality for the following reason. When the input space is high-dimensional, it is easy for it to have a number of variations of interest that is exponential in the number of input dimensions. For example, imagine that we want to distinguish between 10 different values of each input variable (each element of the input vector), and that we care about about all the 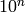 configurations of these
configurations of these 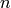 variables. Using only local generalization, we need to see at least one example of each of these configurations in order to be able to generalize to all of them.
variables. Using only local generalization, we need to see at least one example of each of these configurations in order to be able to generalize to all of them.
is close to input example , then the corresponding outputs and should also be close. This is basically the principle used to perform local interpolation. This principle is very powerful, but it has limitations: what if we have to extrapolate? or equivalently, what if the target unknown function has many more variations than the number of training examples? in that case there is no way that local generalization will work, because we need at least as many examples as there are ups and downs of the target function, in order to cover those variations and be able to generalize by this principle. This issue is deeply connected to the so-called curse of dimensionality for the following reason. When the input space is high-dimensional, it is easy for it to have a number of variations of interest that is exponential in the number of input dimensions. For example, imagine that we want to distinguish between 10 different values of each input variable (each element of the input vector), and that we care about about all the configurations of these variables. Using only local generalization, we need to see at least one example of each of these configurations in order to be able to generalize to all of them.Distributed versus Local Representation and Non-Local Generalization
A simple-minded binary local representation of integer 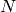 is a sequence of
is a sequence of 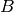 bits such that
bits such that 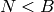 , and all bits are 0 except the -th one. A simple-minded binary distributed representation of integer is a sequence of
, and all bits are 0 except the -th one. A simple-minded binary distributed representation of integer is a sequence of 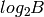 bits with the usual binary encoding for . In this example we see that distributed representations can be exponentially more efficient than local ones. In general, for learning algorithms, distributed representations have the potential to capture exponentially more variations than local ones for the same number of free parameters. They hence offer the potential for better generalization because learning theory shows that the number of examples needed (to achieve a desired degree of generalization performance) to tune
bits with the usual binary encoding for . In this example we see that distributed representations can be exponentially more efficient than local ones. In general, for learning algorithms, distributed representations have the potential to capture exponentially more variations than local ones for the same number of free parameters. They hence offer the potential for better generalization because learning theory shows that the number of examples needed (to achieve a desired degree of generalization performance) to tune 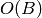 effective degrees of freedom is .
effective degrees of freedom is .
is a sequence of bits such that , and all bits are 0 except the -th one. A simple-minded binary distributed representation of integer is a sequence of bits with the usual binary encoding for . In this example we see that distributed representations can be exponentially more efficient than local ones. In general, for learning algorithms, distributed representations have the potential to capture exponentially more variations than local ones for the same number of free parameters. They hence offer the potential for better generalization because learning theory shows that the number of examples needed (to achieve a desired degree of generalization performance) to tune effective degrees of freedom is .
Another illustration of the difference between distributed and local representation (and corresponding local and non-local generalization) is with (traditional) clustering versus Principal Component Analysis (PCA) or Restricted Boltzmann Machines (RBMs). The former is local while the latter is distributed. With k-means clustering we maintain a vector of parameters for each prototype, i.e., one for each of the regions distinguishable by the learner. With PCA we represent the distribution by keeping track of its major directions of variations. Now imagine a simplified interpretation of PCA in which we care mostly, for each direction of variation, whether the projection of the data in that direction is above or below a threshold. With 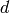 directions, we can thus distinguish between
directions, we can thus distinguish between 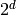 regions. RBMs are similar in that they define hyper-planes and associate a bit to an indicator of being on one side or the other of each hyper-plane. An RBM therefore associates one input region to each configuration of the representation bits (these bits are called the hidden units, in neural network parlance). The number of parameters of the RBM is roughly equal to the number these bits times the input dimension. Again, we see that the number of regions representable by an RBM or a PCA (distributed representation) can grow exponentially in the number of parameters, whereas the number of regions representable by traditional clustering (e.g. k-means or Gaussian mixture, local representation) grows only linearly with the number of parameters. Another way to look at this is to realize that an RBM can generalize to a new region corresponding to a configuration of its hidden unit bits for which no example was seen, something not possible for clustering algorithms (except in the trivial sense of locally generalizing to that new regions what has been learned for the nearby regions for which examples have been seen).
regions. RBMs are similar in that they define hyper-planes and associate a bit to an indicator of being on one side or the other of each hyper-plane. An RBM therefore associates one input region to each configuration of the representation bits (these bits are called the hidden units, in neural network parlance). The number of parameters of the RBM is roughly equal to the number these bits times the input dimension. Again, we see that the number of regions representable by an RBM or a PCA (distributed representation) can grow exponentially in the number of parameters, whereas the number of regions representable by traditional clustering (e.g. k-means or Gaussian mixture, local representation) grows only linearly with the number of parameters. Another way to look at this is to realize that an RBM can generalize to a new region corresponding to a configuration of its hidden unit bits for which no example was seen, something not possible for clustering algorithms (except in the trivial sense of locally generalizing to that new regions what has been learned for the nearby regions for which examples have been seen).
directions, we can thus distinguish between regions. RBMs are similar in that they define hyper-planes and associate a bit to an indicator of being on one side or the other of each hyper-plane. An RBM therefore associates one input region to each configuration of the representation bits (these bits are called the hidden units, in neural network parlance). The number of parameters of the RBM is roughly equal to the number these bits times the input dimension. Again, we see that the number of regions representable by an RBM or a PCA (distributed representation) can grow exponentially in the number of parameters, whereas the number of regions representable by traditional clustering (e.g. k-means or Gaussian mixture, local representation) grows only linearly with the number of parameters. Another way to look at this is to realize that an RBM can generalize to a new region corresponding to a configuration of its hidden unit bits for which no example was seen, something not possible for clustering algorithms (except in the trivial sense of locally generalizing to that new regions what has been learned for the nearby regions for which examples have been seen).TensorRT 2 - Early Access
Deploy faster, more responsive deep learning applications with TensorRT to deliver improved user experience at reduced costs. With FP16 and INT8 optimized precision, deliver up to 3x more throughput, using 61% less memory on applications that rely on high accuracy inference.
TensorRT 2 with INT8 support is now available for pre-release testing through the TensorRT 2 Early Access program. To test this version and provide feedback, please use the "Join now" button below to learn more and apply for the program.
No hay comentarios:
Publicar un comentario